Technical Notes - Q3 2021
Some Observations on ZFS Metadata Special Device
The zpool configuration at rsync.net is simple and straightforward: we create 12 disk raidz-3 vdevs (which can sustain 3 disk failures without data loss) and concatenate them into zpools.
This allows for a nice, even, five vdevs per 60 drive JBOD. 12x16TB disks in one vdev is still a number we (and our retained consultants at Klara Systems[1]) are comfortable with.
We also employ three SSD cache drives per zpool - one single drive for L2ARC and a mirrored pair of drives for the SLOG. This is a very standard configuration and anyone working professionally with ZFS will recognize it.
Recently, however, we had some performance (disk I/O) issues on a system in Zurich that compelled us to look further than this standard model and explore the "special" metadata device class.
The "special" device class (yes, that really is the name and no, we're not sure what the next new device type will be called ... maybe "superspecial" ?) is a vdev that stores only metadata blocks or, if configured metadata blocks and small files of a user configurable size. This vdev, which might be a simple mirror of two SSDs, is part of the actual pool: if it fails, you lose the entire pool.
Let's repeat, and emphasize: unlike an SLOG or L2ARC which are merely inconvenient to lose, if you lose your metadata vdev (your "special" vdev) you will lose your entire zpool just as surely as if you lost one of the other full vdevs
In our case, since we find it acceptable to lose data after four simultaneous drive failures in a vdev we decided to match that fault tolerance in the metadata device by building it out of four mirrored SSDs.
We believe that the risk of "logical failure" of an SSD is higher than the risk of physical failure. This means that some pattern of usage or strange edge-case causes the SSD to die instead of a physical failure. If we are correct, and if we mirror an SSD, then it is possible the two (or three, or four) SSDs will experience identical lifetime usage patterns. To put it simply, it is possible they could all just fail at exactly the same time. The way we mitigate that risk is by building mirrors of SSDs out of similarly spec'd and sized but not identical parts.
For example, the metadata device in question consists of a four-way mirror of these four parts:
Intel SSDSC2KB019TZ01 ("S4520") with 8.8 PB of lifetime writes
Intel SSDSC2KB019T801 ("S4510") with 7.1 PB of lifetime writes
Seagate ZA1920NM10001 ("Ironwolf[2] 110") with 3.5 PB of lifetime writes [2]
Samsung MZ-76P2T0BW ("860 PRO") with 2.4 PB of lifetime writes
In this case we may, indeed, suffer a drive failure at 2.4 PB of write with the Samsung part but I would rather fail out and rebuild a fast SSD than have four fancy Intel parts all die at the same time because they got confused by our workload ...
Here is the zpool command to create this special vdev:
zpool add -f POOLNAME special mirror /dev/da300 /dev/da301 /dev/da302 /dev/da303
At this point, after running the above 'zpool add' command, all new metadata on the pool will be written to this much, much faster vdev. In our case, since we had four existing traditional vdevs made up of spinning disks, we have essentially four "spindles" of write iops - about 600 total iops. Even a very pessimistic measure of one of our SSDs would yield over 20,000 iops.
We can see the device with gstat:
gstat -f "da300|da301|da302|da303"
dT: 1.002s w: 1.000s filter: da300|da301|da302|da303
L(q) ops/s r/s kBps ms/r w/s kBps ms/w %busy Name
0 113 113 495 3.2 0 0 0.0 13.4| da300
0 154 154 631 0.4 0 0 0.0 4.5| da301
0 142 142 583 1.3 0 0 0.0 13.8| da302
0 140 140 580 1.3 0 0 0.0 13.8| da303
... and we can see that it is not (yet) well utilized - only ~560 iops total.
At this point we are simply waiting for the metadata-intensive workload to work its way onto the new device. Metadata previously written to the pool which was read would continue to be read from the spinning disks and would not benefit from the special device. Writing to existing files on the pool would, also, not benefit as their metadata was also already extant on the spinning disks. However, all new file creation would populate the special device with metadata which, from that point on, would be read much, much faster than from the spinning disks.
If you write enough metadata, fast enough, this is probably the final configuration of your metadata special device. However, if your workload consists of one or more zfs datasets that store, and subsequently access, many small files, you can actually store the files themselves on the device - not just the metadata.
For instance, if you have a pool named TANK and a filesystem named fs1 and you want to store all files smaller than, or equal to, 8K in the special vdev, you would run:
zfs set special_small_blocks=8K TANK/fs1
The above command would be run after the special vdev was already created, and running, and specifies that only files in that particular zfs filesystem - not the entire pool smaller than, or equal to, 8k will be stored on the special vdev. These file writes (and later, reads) would then occur much, much faster than from the spinning disks.
The following notes are the result of our conversations with Allan Jude of Klara Systems:
- When sizing the metadata device (special vdev) consider something like 1TB of special vdev per 50TB of storage.
- The special vdev does not require power loss protection (capacitor protected SSDs). "Synchronous writes will go to the SLOG first, but, better SSDs are always better in the long run."
- A 4K file size threshold (special_small_blocks=4K) implies ~250 million files in a 1TB vdev.
- There are NO metrics showing space used in the special vdev by actual metadata vs. small files (special_small_blocks) - if you store small files in this vdev you will not know how much space they are taking up vs. the metadata for the pool.
- No, you cannot evict a filesystem (and the small files it contains) from the special vdev - you would need to delete them from the pool to evict them (or zfs send to a new filesystem, and then destroy the original one).
[1] https://klarasystems.com/
[2] https://twitter.com/rsyncnet/status/1402397708329967618
Chia Coin and Disk Drive Pricing
Chia "is a cryptocurrency where mining is based on the amount of hard disk storage space devoted to it rather than processing power, as with Proof of Work cryptocurrencies such as Bitcoin."[1] Chia first came to our attention at the end of April.
We had been buying 16TB Seagate SAS drives (ST16000NM002G) for $360 and suddenly they were priced at $650. We then began to see headlines and discussions about drive shortages[2] and the impact that this new crypto-currency was having on the market.
Here is a chart of "network space" which shows the disk space dedicated to Chia growing from 1500 Petabytes (PiB) on May 1 to ~36000 PiB on September 8[3]:
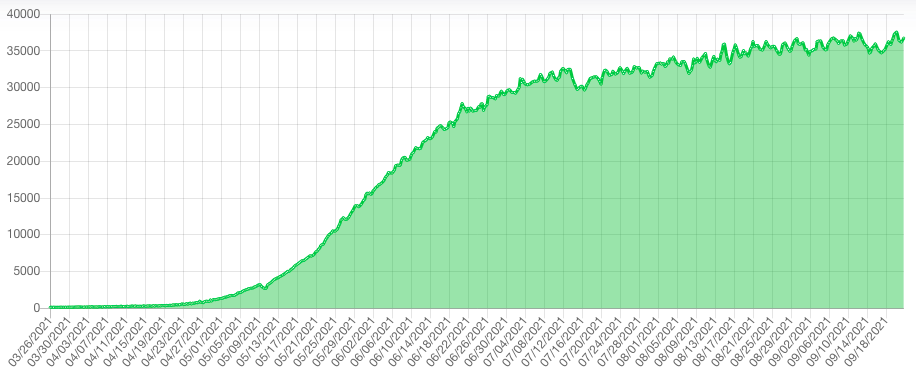
As of this writing, our benchmark (for pricing) disk - the aforementioned ST16000NM002G - is now selling for $405. This is still a >10% premium over "pre-chia" pricing but it is much improved over the peak pricing that we saw.
Interestingly, the price of this disk did not begin to drop until we saw a new model in the channel: The Toshiba MG08SCA16TE (16TB, SAS) entered the retail market a month or so ago at $378 and we then saw the existing models slowly drop to match that price. It appears that the disk drive market has "recovered" from the initial Chia network buildout and that competition in the disk drive market helped to shorten the duration of the price dislocation.
One final note: perhaps the most interesting aspect of Chia (the currency) is that the coin is issued by a company ("Chia Network") which is positioning itself for an IPO. This means that unlike Bitcoin or Ethereum, etc., which can only be short-sold indirectly[4], Chia coin may be possible to short sell directly via the publicly traded equity shares.
[1] https://en.wikipedia.org/wiki/Chia_(cryptocurrency)
[2] https://news.ycombinator.com/item?id=27008295
[3] https://www.chiaexplorer.com/charts/netspace?period=6m
[4] https://www.tbray.org/ongoing/When/202x/2021/06/26/Shorting-Bitcoin
rsync.net as a Litestream SFTP target
Litestream is a standalone streaming replication tool for SQLite.[1] It allows you to continuously stream SQLite changes to an offsite target.
In May, they added a SFTP replica type that allows users to back up to "services like rsync.net".[2]
You can read more about Litestream at litestream.io
[1] https://github.com/benbjohnson/litestream
[2] https://github.com/benbjohnson/litestream/issues/140
Some Interesting Commands
We maintain a full complement of checksum commands that you can run, over ssh, to verify files:
ssh user@rsync.net rmd160 some/file
md5
sha1
sha224
sha256
sha384
sha512
sha512t256
rmd160
skein256
skein512
skein1024
cksum
... and note the last one in the list, 'cksum' ...
cksum is interesting because if your use-case is not security or collision detection but, rather, simple verification of file transfer and/or integrity, cksum is much, much faster than the "serious" checksum tools. You should consider cksum if you have simple integrity checks to do on millions of files, etc.
More Information
rsync.net publishes a wide array of support documents as well as a FAQ
rsync.net has been tested, reviewed and discussed in a variety of venues.
You, or your CEO, may find our CEO Page useful.
Please see our HIPAA, GDPR, and Sarbanes-Oxley compliance statements.
Contact info@rsync.net for more information, and answers to your questions.

